
Table des matières :
Je rencontre un nombre important de personnes qui se lancent dans le SEO sans forcément avoir de ressources financières importantes pour acheter des logiciels ou souscrire à des outils en ligne qui permettent d’analyser en masse une multitude de critères. Je vais vous mettre à disposition aujourd’hui un script PHP qui permet de scrapper les SERP Google (résultats de recherche sur google.fr dans notre cas) et de récupérer les informations principales : date, position, URL positionnée, balise <title>, et meta description (snippet)C’est un script assez simple, en procédural (comme ça les débutants en PHP peuvent le modifier facilement) qui permettra de récupérer dans les résultats google.fr les principales informations utiles en SEO.
Il est open source donc si vous souhaitez le modifier, vous êtes libres. Pour celles et ceux qui s’intéressent à PHP, je vous conseille PHP.net qui est le portail officiel de la documentation de ce langage. Si vous recherchez des offres intéressantes, lesJeudis.com est pour moi un des meilleurs sites d’offres d’emploi dans ce secteur.
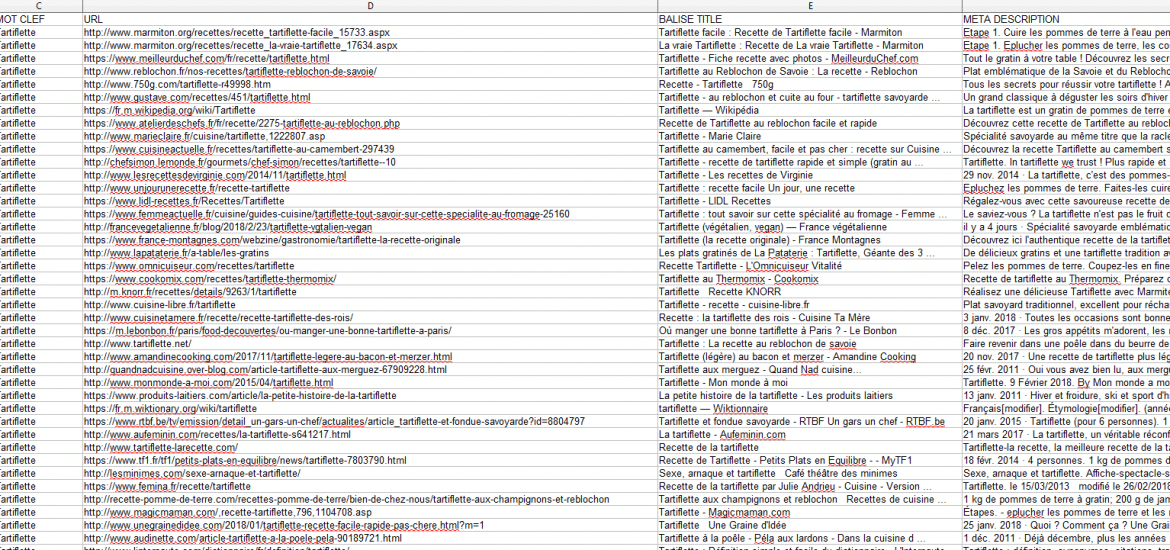
Le script va aller récupérer les résultats de recherche sur google.fr de la liste de mots clefs que vous avez renseigné et extraire les principales informations pour les enregistrer dans un fichiers *.csv qui contiendra :
- Date
- Position de l’url
- URL qui se positionne
- Balise <title> : titre de la page
- Snippet : c’est le texte gris qui correspond généralement à la balise meta description
Par défaut il récupère les 50 premiers résultats (modifiable) et pourra scrapper Google en version Desktop ou mobile.
Le fichier *.csv ressemble à ça :

Deux exports peuvent êtres téléchargés à ces URL :
- https://www.jeromeweb.net/wp-content/uploads/2018/02/2018-02-27_desktop.csv
- https://www.jeromeweb.net/wp-content/uploads/2018/02/2018-02-27_desktop.csv
A quoi sert il?
Comme chaque referenceur à sa propre méthode de travail, il peut être utilisé de multiples manières, surtout pour ceux qui le customiseraient.
Voici les principales :
- Récupérer en masse les URL de SERP
- Récupérer en masse les <title> : par exemple pour analyser la concurrence pour optimiser au mieux son URL
- Récupérer en masse les snippets : par exemple pour analyser la concurrence pour optimiser au mieux son URL
- Suivre son positionnement : solution de fortune quand on n’a pas la possibilité de prendre des outils dédiés comme Rank Tracker
L’avantage surtout est d’avoir un script à disposition qui tourne sur n’importe quel serveur local ou mutualisé même si l’on n’a pas accès à nos logiciels.
Installation du script
Serveur
Ce script a besoin d’être exécuté sur un serveur qui interprète le PHP. Vous pouvez l’installer en local sur votre ordinateur (Wamp Server, Easy PHP, …) ou sur un serveur mutualisé chez la plupart des hébergeurs. La seule contrainte est d’avoir la librairie libcurl d’activée afin de pouvoir cURLer (comprendre « lire ») des url distantes. On aurait pu le faire avec la fonction file_get_contents() mais Google la bloque et la gestion des proxys n’est pas supportée.
Proxys
Les proxys ne sont pas obligatoires, surtout si vous lancez le script depuis un serveur local et que vous récupérez juste quelques mots clefs par jour. Je vous mets en garde sur 1 point quand même : en local et sans proxy, c’est votre adresse IP qui va consulter Google de multiples fois donc il y a un risque de blocage.
Sur un mutualisé, le proxy est obligatoire car il y a 99.99% de chance que l’adresse du serveur soit déjà blacklistée sur google.
Si vous avez un serveur dédié, c’est le même principe qu’en local : pas obligatoire pour des petits besoins mais attention à l’IP.
J’utilise quotidiennement des proxys pour mes besoins professionnels et je vous recommande Buyproxies : l’avantage c’est qu’ils proposent des proxys Français qui sont désormais obligatoires pour avoir des résultats cohérents. Il faut prendre des « Dedicated proxies » avec location « Europe » et ensuite contacter le support pour avoir des proxys Français. Le cout est assez raisonnable : 10 $ USD par mois pour 5 proxys.
Execution
Ce script se compose de plusieurs fichiers : il faudra tous les mettre dans le même répertoire sur le serveur.
- scrap_google_proxys.txt : si vous utilisez des proxys, il faudra renseigner les informations de connexion à ces derniers dans ce fichier.
Le format est le suivant : ip:port:login:mdp
1 proxy par ligne
Si vous n’utilisez pas de proxy : laissez le vide - scrap_google_keywords.txt : c’est le fichier qui va contenir les mots clefs à consulter sur google.fr
C’est très simple : 1 mots clef / ligne - scrap_google.php : c’est le fichier principal, celui que vous devez lancer dans votre navigateur.
- http://monserveur.xx/scrap_google.php : lancera le scrap et la récupération des informations de la totalité des mots clefs renseignés dans le fichier scrap_google_keywords.txt en version DESKTOP
- http://monserveur.xx/scrap_google.php?mobile=mobile : lancera le scrap et la récupération des informations de la totalité des mots clefs renseignés dans le fichier scrap_google_keywords.txt en version MOBILE
Avec 1 bon proxy, vous pouvez facilement récupérer les informations de 10 mots clefs, des dizaines de fois par jour. Tout dépend quand même du délai (par défaut 2 secondes) et des mots clefs consultés : sur certains, google bloque les proxys plus vite.
Voilà ce que fait le script en détail :
- Si des proxys sont renseignés, 1 est choisi au hasard
- Le User-Agent (UA) est définit en fonction du choix de l’utilisateur : desktop ou mobile
- Pour chaque mot clef renseigné dans le fichier *.txt
- Scrap de google.fr
- Extraction des informations
- Enregistrement des informations et de la SERP dans un fichier *.html
- Création du fichier *.csv qui est ensuite importable dans Excel / open Office
Le script va s’arrêter si il ne trouve pas le fichier obligatoire scrap_google_keywords.txt ou si il n’arrive pas à scrapper Google (IP ou proxy utilisé bloqué). Dans ce cas, des messages d’erreur apparaitront à l’écran.
Telechargez gratuitement le *.zip contenant les fichiers : https://www.jeromeweb.net/rxo0

Entrepreneur et Geek depuis plus de 20 ans.
Très très sympas ton scraper google: Good Job !!
Good Job merci
Bonjour,
L’article a 2 ans, est-ce que le script fonctionne encore ?
En tout cas, test avec WAMP en local, pas de proxy, ne semble pas marcher.
Merci !
@etienne je vais vérifier rapidement et je te tiens au courant
Bonjour,
Est-ce que le script est toujours disponible et fonctionne toujours ?
merci